- آیا تجزیه و تحلیل فنی در بازار روسیه کار می کند؟بینش از سهام مؤلفه شاخص MSEX (MOEX روسیه)
- اقتصاد جریان اصلی از بین رفته است ، و قیمت هرج و مرج سیاسی است
- محاسبه تسلط بیت کوین
- آیا می خواهید با رمزنگاری ثروت ایجاد کنید؟سپس Shiba Inu (Shib) ، Renq Finance (RENQ) و Dogecoin (Doge) را بخرید
- گردش مالی تجارت: چیست و چرا مهم است؟
- وقتی کارگزار سهام شما شما را فریب می دهد چه باید کرد؟|Zerodha/Upstox
- لانچ پد XYZ پیش بینی قیمت 2023 - 2030
- 9 راه برای کسب درآمد آنلاین
- سوالات و پاسخ های مدارهای آنالوگ-هارتلی اسیلاتو ر-2
- ثبت نام

آخرین مطالب
امکانات وب


منتشر شده در 25 فوریه 2020 توسط Rebecca Bevans. بازبینی شده در 15 نوامبر 2022.
رگرسیون خطی یک مدل رگرسیونی است که از یک خط مستقیم برای توصیف رابطه بین متغیرها استفاده می کند. با جستجوی مقدار ضریب(های) رگرسیون که خطای کل مدل را به حداقل می رساند، خط بهترین تناسب را از طریق داده های شما پیدا می کند.
دو نوع اصلی رگرسیون خطی وجود دارد:
- رگرسیون خطی ساده تنها از یک متغیر مستقل استفاده می کند
- رگرسیون خطی چندگانه از دو یا چند متغیر مستقل استفاده می کند
در این راهنمای گام به گام، با استفاده از دو مجموعه داده نمونه، شما را از طریق رگرسیون خطی در R راهنمایی خواهیم کرد.
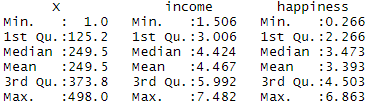
باز هم، چون متغیرها کمی هستند، اجرای کد یک خلاصه عددی از دادههای متغیر مستقل (سیگار کشیدن و دوچرخهسواری) و متغیر وابسته (بیماری قلبی) را تولید میکند:

از سرقت ادبی جلوگیری کنید، یک چک رایگان انجام دهید.
مرحله 2: مطمئن شوید که داده های شما مطابق با مفروضات هستند
میتوانیم از R برای بررسی اینکه دادههای ما با چهار فرض اصلی برای رگرسیون خطی مطابقت دارند، استفاده کنیم.
رگرسیون ساده
- استقلال مشاهدات (با نام مستعار بدون خود همبستگی)
از آنجایی که ما فقط یک متغیر مستقل و یک متغیر وابسته داریم، نیازی به آزمایش هیچ رابطه پنهانی بین متغیرها نداریم.
اگر میدانید که درون متغیرها همبستگی خودکار دارید (یعنی مشاهدات متعدد از یک موضوع آزمایشی)، پس با یک رگرسیون خطی ساده ادامه ندهید! به جای آن از یک مدل ساختاریافته، مانند یک مدل خطی با اثرات مختلط استفاده کنید.
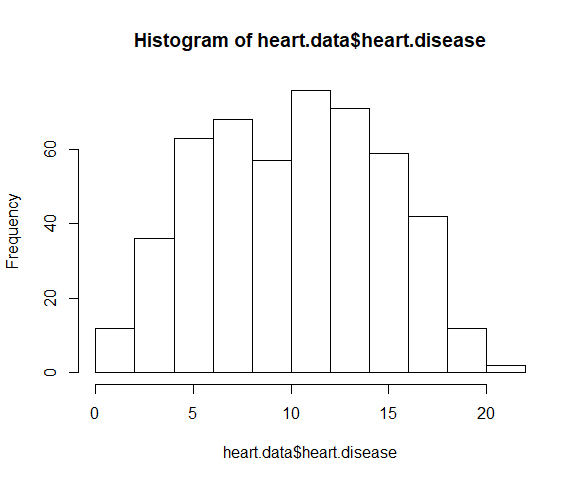
برای بررسی اینکه آیا متغیر وابسته از توزیع نرمال پیروی می کند، از تابع hist() استفاده کنید.
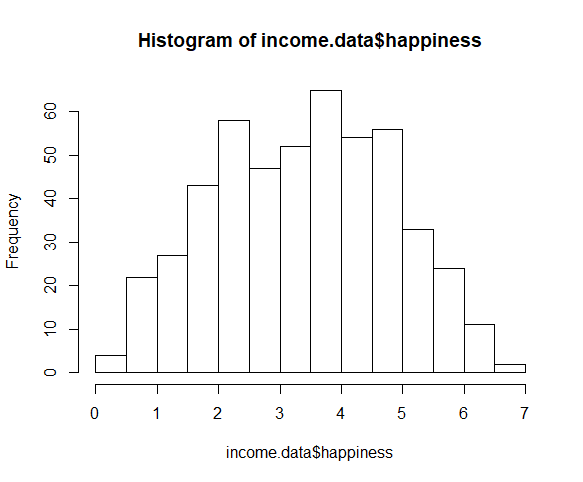
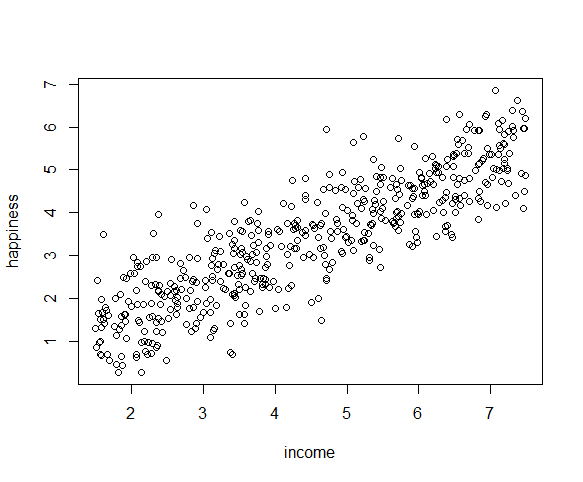
این رابطه تقریباً خطی به نظر می رسد، بنابراین می توانیم با مدل خطی ادامه دهیم.
- همسانی (همگنی واریانس)
این بدان معناست که خطای پیشبینی در محدوده پیشبینی مدل بهطور قابلتوجهی تغییر نمیکند. ما می توانیم این فرض را بعد از برازش مدل خطی آزمایش کنیم.
رگرسیون چندگانه
- استقلال مشاهدات (با نام مستعار بدون خود همبستگی)
از تابع cor() برای تست رابطه بین متغیرهای مستقل خود استفاده کنید و مطمئن شوید که آنها خیلی همبستگی ندارند.
خروجی به شکل زیر است:
این جدول خروجی ابتدا معادله مدل را ارائه می دهد، سپس باقیمانده های مدل را خلاصه می کند (مرحله 4 را ببینید).
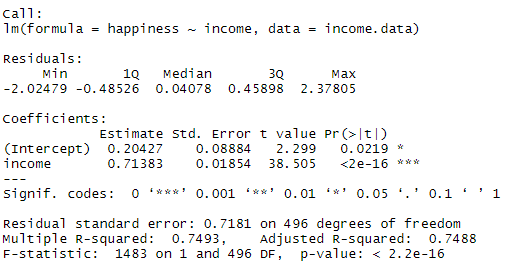
بخش ضرایب نشان می دهد:
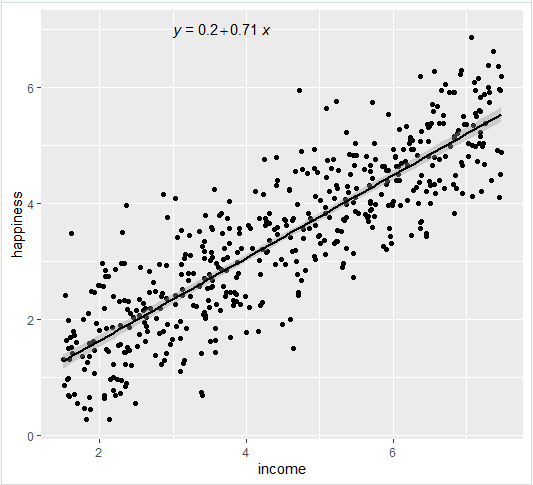
- برآوردها (تخمین) برای پارامترهای مدل - مقدار فاصله y (در این مورد 0. 204) و اثر تخمینی درآمد بر شادی (0. 713).
- خطای استاندارد مقادیر تخمین زده شده (Error Std.).
- آمار آزمون (مقدار t ، در این مورد آمار t).
- The p value ( Pr(>|t |)) ، در صورتی که فرضیه تهی هیچ رابطه ای صحیح نباشد ، احتمال یافتن آمار t داده شده را پیدا می کند.
سه خط پایانی تشخیص مدل هستند-مهمترین نکته قابل توجه ، مقدار P (در اینجا 2. 2E-16 یا تقریبا صفر است) ، که نشان می دهد مدل متناسب با داده ها است یا خیر.
از این نتایج می توان گفت که بین درآمد و خوشبختی رابطه مثبت معنی داری وجود دارد (ارزش P<0.001), with a 0.713-unit (+/- 0.01) increase in happiness for every unit increase in income.
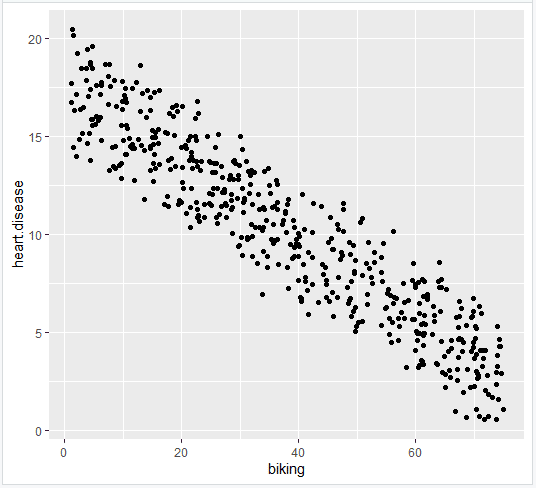
رگرسیون چندگانه: دوچرخه سواری ، سیگار کشیدن و بیماری قلبی
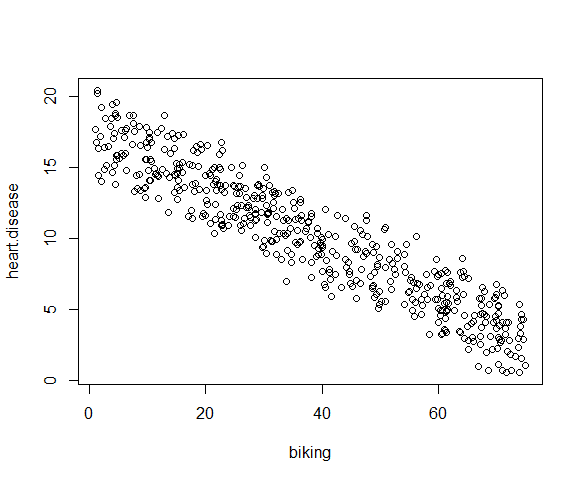
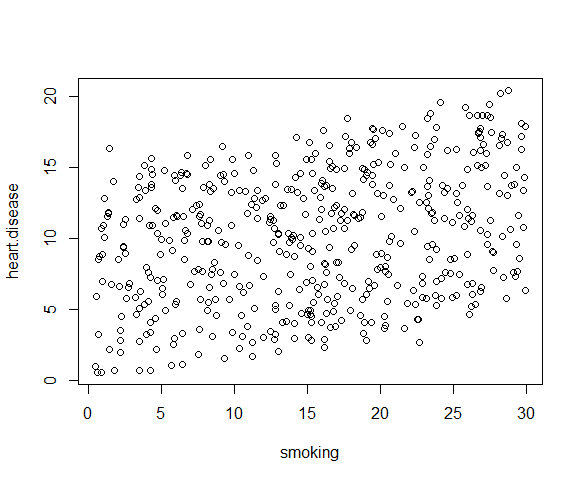
بیایید ببینیم آیا رابطه خطی بین دوچرخه سواری به کار ، سیگار کشیدن و بیماری های قلبی در بررسی خیالی ما از 500 شهر وجود دارد یا خیر. نرخ دوچرخه سواری به کار بین 1 تا 75 ٪ ، میزان استعمال دخانیات بین 0. 5 تا 30 ٪ و میزان بیماری قلبی بین 0. 5 تا 20. 5 ٪ است.
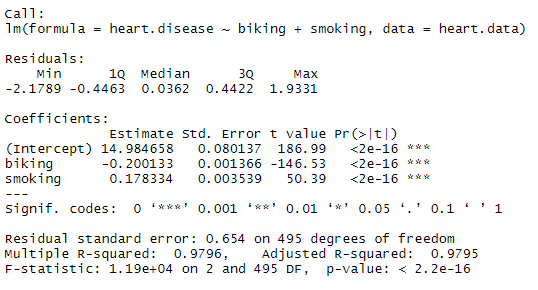
برای آزمایش رابطه ، ابتدا یک مدل خطی را با بیماری قلبی به عنوان متغیر وابسته و دوچرخه سواری و سیگار کشیدن به عنوان متغیرهای مستقل قرار می دهیم. این دو خط کد را اجرا کنید:
توجه داشته باشید که دستور par (mfrow ()) پنجره توطئه ها را به تعداد ردیف ها و ستون های مشخص شده در براکت ها تقسیم می کند. بنابراین par (mfrow = c (2،2)) آن را به دو ردیف و دو ستون تقسیم می کند. برای بازگشت به ترسیم یک نمودار در کل پنجره ، دوباره پارامترها را تنظیم کرده و (2،2) را با (1،1) جایگزین کنید.
این توطئه های باقیمانده تولید شده توسط کد است:
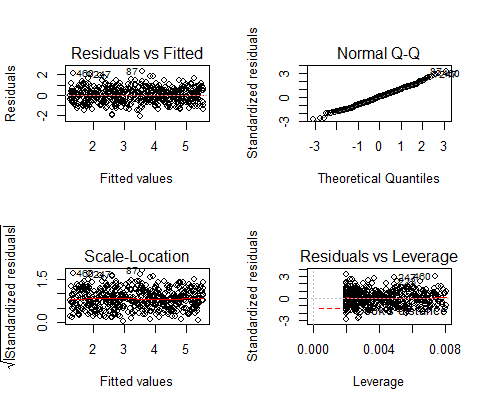
باقیمانده واریانس غیر قابل توضیح است. آنها دقیقاً مشابه خطای مدل نیستند ، اما از آن محاسبه می شوند ، بنابراین دیدن تعصب در باقیمانده ها همچنین نشانگر تعصب در خطا است.
مهمترین چیزی که باید به دنبال آن باشید این است که خطوط قرمز نشان دهنده میانگین باقیمانده ها اساساً افقی و محور صفر هستند. این بدان معناست که در داده هایی که باعث می شود رگرسیون خطی نامعتبر باشد ، هیچ گونه تعصب و تعصب وجود ندارد.
در q-qplot معمولی در بالا سمت راست ، می توانیم ببینیم که باقیمانده های واقعی از مدل ما یک خط تقریباً یک به یک با باقیمانده های نظری از یک مدل کامل تشکیل می دهند.
بر اساس این باقیمانده ها ، می توان گفت که مدل ما فرض همواسکوسی بودن را برآورده می کند.
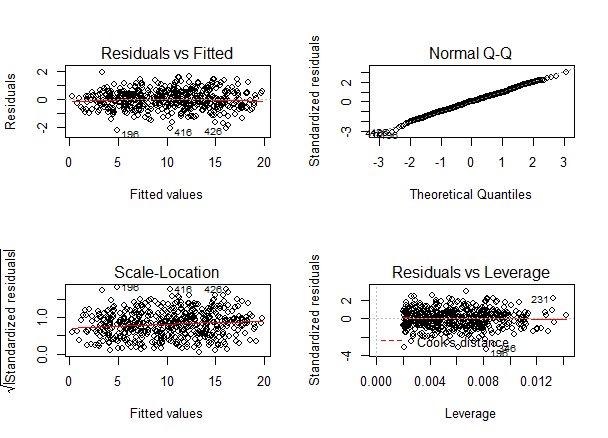
رگرسیون چندگانه
باز هم ، ما باید بررسی کنیم که مدل ما در واقع مناسب برای داده ها است ، و با اجرای این کد ، در خطای مدل تنوع زیادی نداریم:
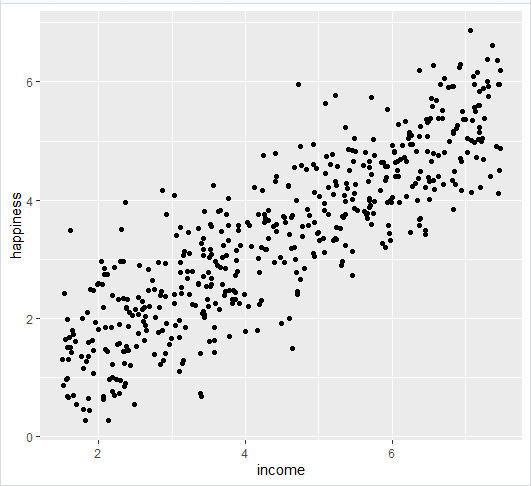
- خط رگرسیون خطی را به داده های ترسیم شده اضافه کنید
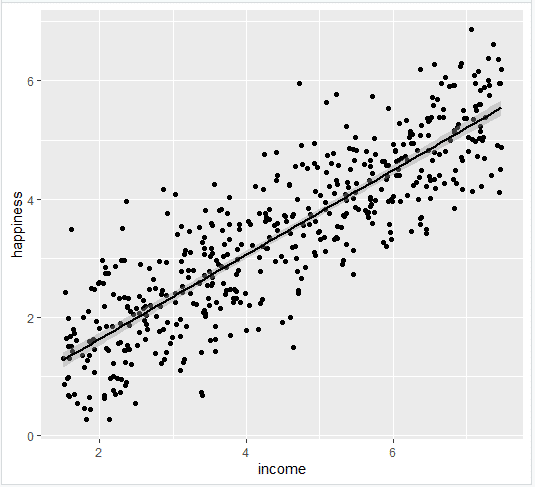
خط رگرسیون را با استفاده از geom_smooth () اضافه کرده و در LM به عنوان روش خود برای ایجاد خط تایپ کنید. با این کار خط رگرسیون خطی و همچنین خطای استاندارد تخمین (در این مورد +/- 0. 01) به عنوان یک نوار خاکستری روشن در اطراف خط اضافه می شود:
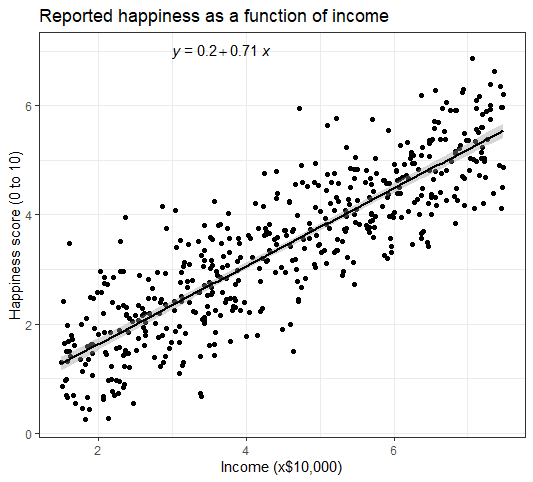
- نمودار را برای انتشار آماده کنید
ما می توانیم پارامترهای سبک را با استفاده از theme_bw () و تهیه برچسب های سفارشی با استفاده از آزمایشگاه ها () اضافه کنیم.
این کار جدیدی در کنسول شما ایجاد نمی کند ، اما باید یک قاب داده جدید را در برگه محیط مشاهده کنید. برای مشاهده آن روی آن کلیک کنید.
- مقادیر بیماری قلبی را بر اساس مدل خطی خود پیش بینی کنید
در مرحله بعد ، مقادیر "پیش بینی شده Y" خود را به عنوان یک ستون جدید در مجموعه داده ای که تازه ایجاد کرده ایم ذخیره خواهیم کرد.
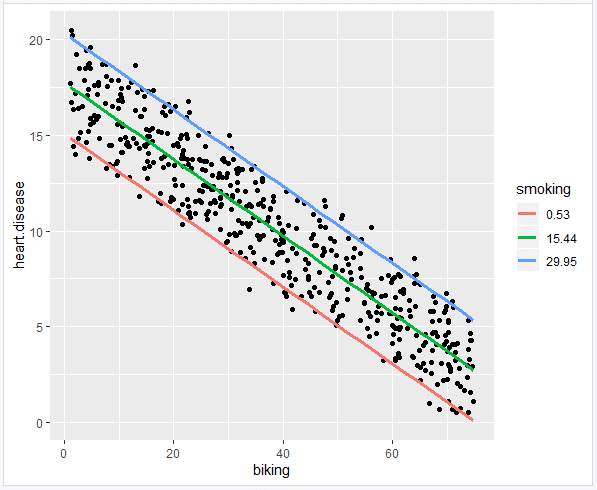
این نمودار تمام شده است که می توانید در مقالات خود درج کنید!
مرحله 6: نتایج خود را گزارش دهید
علاوه بر نمودار ، شامل یک عبارت مختصر است که نتایج مدل رگرسیون را توضیح می دهد.
با گزارش نتایج رگرسیون خطی ساده ، ما بین درآمد و خوشبختی رابطه معنی داری پیدا کردیم (P<0.001, R 2 = 0.73 ± 0.0193), with a 0.73-unit increase in reported happiness for every $10,000 increase in income. Reporting the results of multiple linear regression In our survey of 500 towns, we found significant relationships between the frequency of biking to work and the frequency of heart disease and the frequency of smoking and frequency of heart disease ( p <0 and p <0.001, respectively).
به طور خاص ، ما در فرکانس بیماری قلبی برای هر 1 ٪ افزایش دوچرخه سواری ، 0. 2 ٪ کاهش یافتیم.
این مقاله Scribbr را ذکر کنید
اگر می خواهید این منبع را استناد کنید ، می توانید استناد را کپی و جایگذاری کنید یا بر روی دکمه "استناد به این مقاله Scribbr" کلیک کنید تا به طور خودکار استناد را به ژنراتور استناد رایگان ما اضافه کنید.
استراتژیهای اسکالپ...
ما را در سایت استراتژیهای اسکالپ دنبال می کنید
برچسب : نویسنده : ناصر تقوایی بازدید : 92
آرشیو مطالب
پيوندهای روزانه
خبرنامه
