- آیا تجزیه و تحلیل فنی در بازار روسیه کار می کند؟بینش از سهام مؤلفه شاخص MSEX (MOEX روسیه)
- اقتصاد جریان اصلی از بین رفته است ، و قیمت هرج و مرج سیاسی است
- محاسبه تسلط بیت کوین
- آیا می خواهید با رمزنگاری ثروت ایجاد کنید؟سپس Shiba Inu (Shib) ، Renq Finance (RENQ) و Dogecoin (Doge) را بخرید
- گردش مالی تجارت: چیست و چرا مهم است؟
- وقتی کارگزار سهام شما شما را فریب می دهد چه باید کرد؟|Zerodha/Upstox
- لانچ پد XYZ پیش بینی قیمت 2023 - 2030
- 9 راه برای کسب درآمد آنلاین
- سوالات و پاسخ های مدارهای آنالوگ-هارتلی اسیلاتو ر-2
- ثبت نام

آخرین مطالب
امکانات وب


توضیح عمیق Gradient Descent، و نحوه جلوگیری از مشکلات مینیمم های محلی و نقاط زین.
5 سال پیش • 14 دقیقه خواندن
اعتبار تصویر: رسانه O'Reilly
یادگیری عمیق، تا حد زیادی، در واقع در مورد حل مشکلات عظیم بهینه سازی است. یک شبکه عصبی صرفاً یک تابع بسیار پیچیده است که از میلیون ها پارامتر تشکیل شده است که یک راه حل ریاضی برای یک مسئله را نشان می دهد. وظیفه طبقه بندی تصاویر را در نظر بگیرید. AlexNet یک تابع ریاضی است که آرایه ای را به نمایش می گذارد که مقادیر RGB یک تصویر را نشان می دهد و خروجی را به صورت دسته ای از امتیازات کلاس تولید می کند.
منظور ما از آموزش شبکه های عصبی اساساً به حداقل رساندن یک تابع از دست دادن است. مقدار این تابع از دست دادن به ما اندازه گیری می کند که عملکرد شبکه ما در یک مجموعه داده مشخص چقدر از کامل فاصله دارد.
تابع ضرر
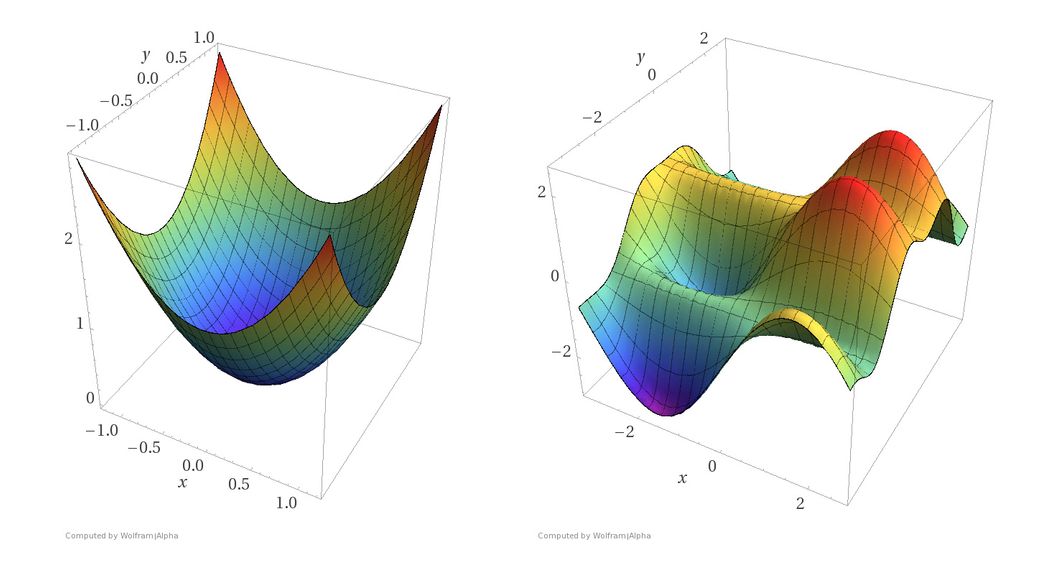
اجازه دهید، برای سادگی، فرض کنیم شبکه ما فقط دو پارامتر دارد. در عمل، این عدد حدود یک میلیارد خواهد بود، اما ما همچنان به مثال دو پارامتری در طول پست پایبند خواهیم بود تا هنگام تلاش برای تجسم چیزها، خودمان را دیوانه نکنیم. اکنون، شمارش یک تابع ضرر بسیار خوب ممکن است به این شکل باشد.
کانتور یک تابع از دست دادن
چرا من می گویم یک تابع ضرر بسیار خوب؟از آنجا که یک تابع از دست دادن دارای یک کانتور مانند بالا مانند سانتا است، وجود ندارد. با این حال، هنوز هم به عنوان یک ابزار آموزشی مناسب برای دریافت برخی از مهم ترین ایده ها در مورد نزول گرادیان در سراسر هیئت عمل می کند. پس اجازه بدهید به این کار برسیم!
محورهای x و y مقادیر دو وزن را نشان می دهند. محور z مقدار تابع ضرر را برای مقدار خاصی از دو وزن نشان می دهد. هدف ما یافتن مقدار خاصی از وزن است که برای آن کاهش حداقل است. چنین نقطه ای حداقل برای تابع ضرر نامیده می شود.
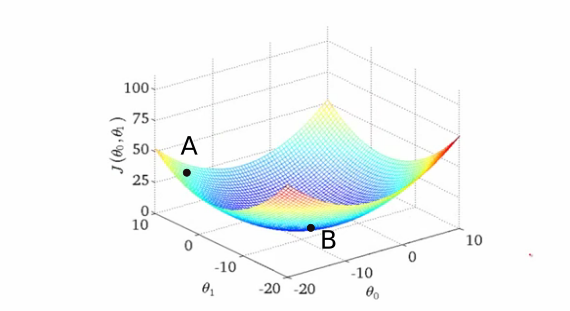
شما در ابتدا وزن ها را به طور تصادفی مقداردهی کرده اید، بنابراین شبکه عصبی شما احتمالاً مانند یک نسخه مست از خودتان رفتار می کند و تصاویر گربه ها را به عنوان انسان طبقه بندی می کند. چنین وضعیتی با نقطه A در کانتور مطابقت دارد، جایی که شبکه عملکرد بدی دارد و در نتیجه تلفات زیاد است.
ما باید راهی پیدا کنیم تا به نحوی به انتهای "دره" به نقطه B برویم، جایی که تابع ضرر دارای حداقل است؟خب چطور باید انجامش بدیم؟
گرادیان نزول
گرادیان نزول
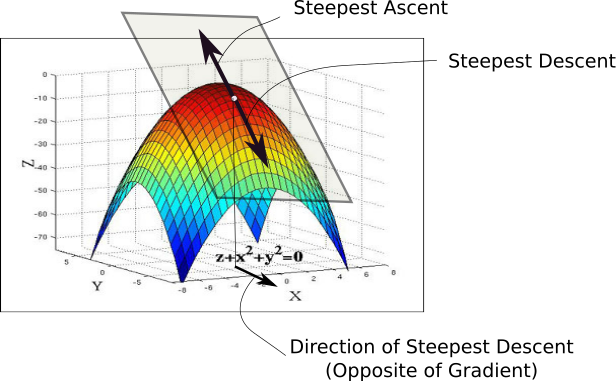
وقتی وزنهای خود را آغاز می کنیم ، در نقطه A در چشم انداز ضرر قرار می گیریم. اولین کاری که ما انجام می دهیم این است که از همه جهت های ممکن در هواپیمای X-Y بررسی کنیم ، حرکت در طول آن جهت باعث کاهش شدیدترین مقدار عملکرد ضرر می شود. این مسیری است که ما باید به آن حرکت کنیم. این جهت دقیقاً بر خلاف جهت شیب انجام می شود. شیب ، پسر عموی ابعادی بالاتر مشتق ، با صعود شدید به ما جهت می دهد.
برای پیچیدن سر خود در اطراف آن ، شکل زیر را در نظر بگیرید. در هر نقطه از منحنی ما ، می توانیم هواپیمایی را تعریف کنیم که مماس باشد تا نقطه. در ابعاد بالاتر ، ما همیشه می توانیم یک هایپرپلن را تعریف کنیم ، اما اکنون بیایید به 3-D بچسبیم. سپس ، ما می توانیم در این هواپیما مسیرهای نامتناهی داشته باشیم. از بین آنها ، دقیقاً یک جهت به ما جهت می دهد که عملکرد در آن صعود شدید داشته باشد. این جهت توسط شیب ارائه شده است. جهت مخالف آن جهت نزول شدید است. اینگونه است که الگوریتم نام خود را می گیرد. ما نزول را در جهت گرادیان انجام می دهیم ، از این رو ، آن را نزول شیب نامیده می شود.
اکنون ، هنگامی که ما مسیری را که می خواهیم حرکت کنیم ، باید اندازه گامی را که باید برداریم تصمیم بگیریم. اندازه این مرحله نرخ یادگیری نامیده می شود. ما باید آن را با دقت انتخاب کنیم تا اطمینان حاصل کنیم که می توانیم به حداقل برسیم.
اگر خیلی سریع پیش برویم ، ممکن است مینیما را تحت الشعاع قرار دهیم و در امتداد پشته های "دره" تندرستیم بدون اینکه هرگز به حداقل برسیم. خیلی آهسته بروید ، و ممکن است تمرین خیلی طولانی باشد تا اصلاً امکان پذیر باشد. حتی اگر اینگونه نباشد ، نرخ یادگیری بسیار کند باعث می شود که الگوریتم مستعد بیشتر در حداقل باشد ، چیزی که بعداً در این پست پوشش خواهیم داد.
هنگامی که ما شیب و میزان یادگیری خود را داریم ، یک قدم برداشته و شیب را در هر موقعیتی که به آن پایان می دهیم ، دوباره به دست می آوریم و روند را تکرار می کنیم.
در حالی که جهت گرادیان به ما می گوید که صعود شدیدترین جهت چیست ، بزرگی به ما می گوید صعود/نزول شدیدترین شیب دار است. بنابراین ، در حداقل ، جایی که کانتور تقریباً مسطح است ، انتظار دارید که شیب تقریباً صفر باشد. در واقع ، دقیقاً برای نقطه حداقل صفر است.
نزول شیب در عمل
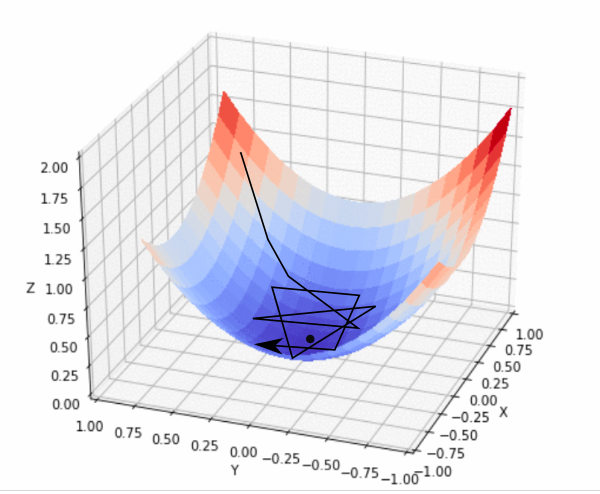
استفاده از نرخ یادگیری خیلی بزرگ
در عمل، ممکن است هرگز دقیقاً به مینیمم نرسیدیم، اما همچنان در یک ناحیه مسطح در مجاورت مینیمم در نوسان هستیم. همانطور که ما این منطقه خود را نوسان می کنیم، ضرر تقریباً حداقل چیزی است که می توانیم به دست آوریم، و تغییر چندانی نمی کند زیرا ما فقط در اطراف حداقل واقعی حرکت می کنیم. اغلب، زمانی که مقادیر ضرر در تعداد از پیش تعیین شده، مثلاً 10 یا 20 تکرار، بهبود نیافته اند، تکرارهای خود را متوقف می کنیم. وقتی چنین اتفاقی می افتد، می گوییم تمرینات ما همگرا شده است یا همگرایی صورت گرفته است.
یک اشتباه رایج
بگذارید یک لحظه منحرف شوم. اگر برای تجسم نزول گرادیان در گوگل جستجو کنید، احتمالاً مسیری را خواهید دید که از یک نقطه شروع می شود و به حداقل می رسد، درست مانند انیمیشن ارائه شده در بالا. با این حال، این یک تصویر بسیار نادرست از اینکه شیب نزول واقعا چیست به شما می دهد. مسیری که ما می گیریم به طور کامل به صفحه x-y محدود می شود، صفحه ای که وزن ها را در بر می گیرد.
همانطور که در انیمیشن بالا نشان داده شده است، شیب نزول به هیچ وجه شامل حرکت در جهت z نیست. این به این دلیل است که فقط وزن ها پارامترهای آزاد هستند که با جهت های x و y توصیف می شوند. مسیر واقعی که می گیریم در صفحه x-y به صورت زیر تعریف می شود.
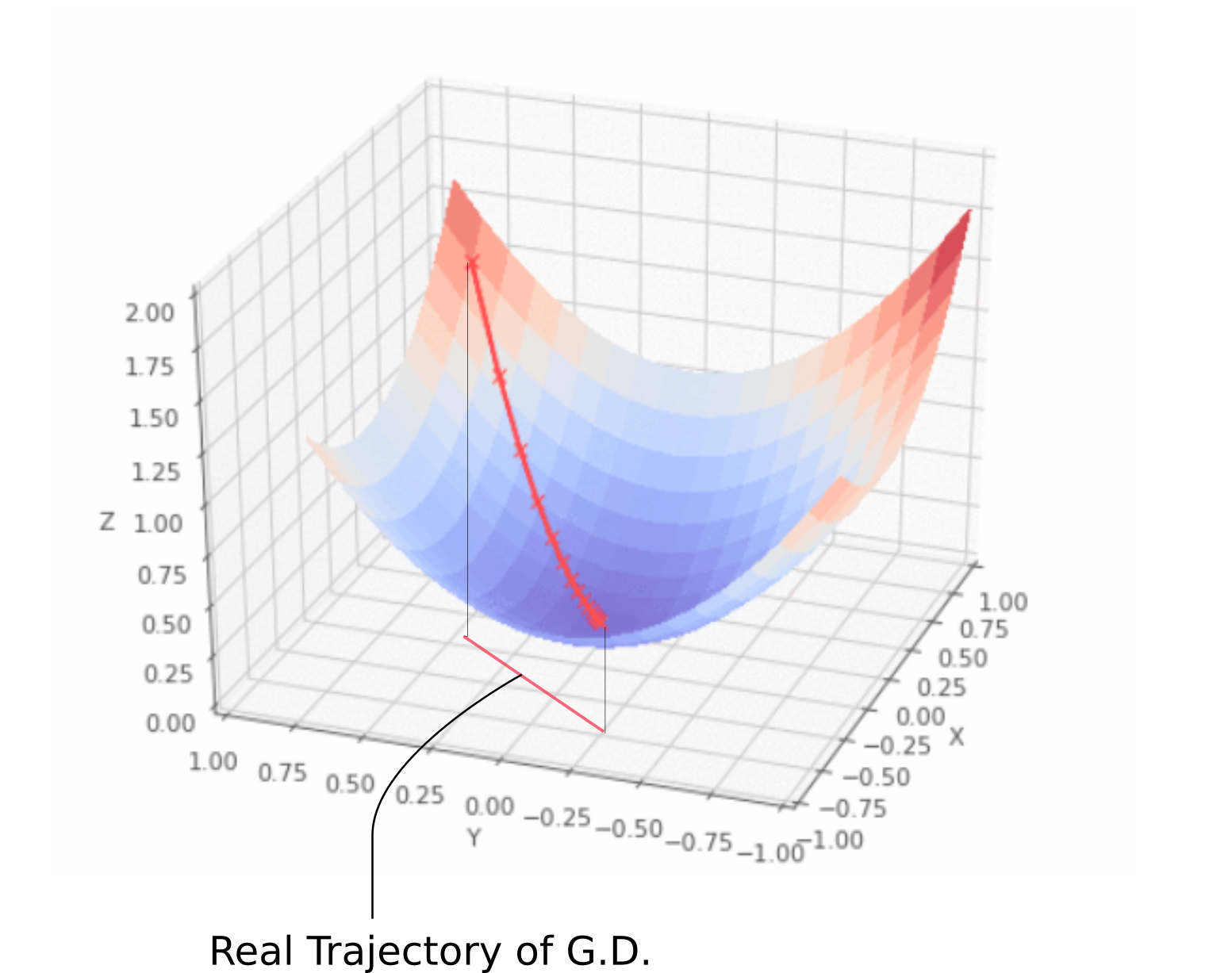
مسیر نزول شیب واقعی
هر نقطه در صفحه x-y نشان دهنده یک ترکیب منحصر به فرد از وزن است، و ما می خواهیم مجموعه ای از وزن ها را با حداقل ها توصیف کنیم.
معادلات پایه
معادله اصلی که قانون به روز رسانی گرادیان نزول را توصیف می کند.
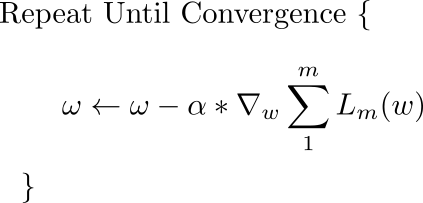
این به روز رسانی در طول هر تکرار انجام می شود. در اینجا w بردار وزن است که در صفحه x-y قرار دارد. از این بردار، گرادیان تابع از دست دادن را با توجه به وزن های ضرب در آلفا، نرخ یادگیری کم می کنیم. گرادیان بردار است که جهتی را به ما می دهد که در آن تابع افت شدیدترین صعود را دارد. جهت تندترین نزول جهتی است که دقیقاً مخالف گرادیان است و به همین دلیل است که بردار گرادیان را از بردار وزن کم می کنیم.
اگر تصور بردارها برای شما کمی سخت است، تقریباً همان قانون به روز رسانی برای هر وزن شبکه به طور همزمان اعمال می شود. تنها تغییر این است که از آنجایی که ما اکنون به روزرسانی را به صورت جداگانه برای هر وزن انجام می دهیم، گرادیان در معادله بالا با پیش بینی بردار گرادیان در امتداد جهت نشان داده شده توسط وزن خاص جایگزین می شود.
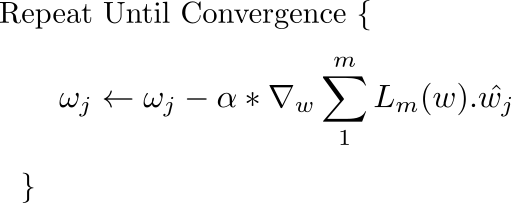
این به روز رسانی به طور همزمان برای تمام وزن ها انجام می شود.
قبل از تفریق ، بردار شیب را با نرخ یادگیری ضرب می کنیم. این نشان دهنده گامی است که قبلاً در مورد آن صحبت کردیم. درک کنید که حتی اگر نرخ یادگیری را ثابت نگه داریم ، اندازه مرحله به دلیل تغییر در بزرگی شیب ، می تواند تغییر کند ، اما از افزایش کانتور ضرر برخوردار است. با نزدیک شدن به حداقل ، گرادیان به صفر نزدیک می شوند و قدم های کوچکتر و کوچکتر را به سمت حداقل می کشیم.
از نظر تئوری ، این خوب است ، زیرا ما می خواهیم الگوریتم با نزدیک شدن به حداقل ، اقدامات کمتری انجام دهد. داشتن یک اندازه پله بیش از حد بزرگ ممکن است باعث شود که بیش از حد بیش از حد باشد و بین پشته های مینیما گزاف گویی کند.
یک تکنیک گسترده در نزول شیب ، داشتن نرخ یادگیری متغیر است نه یک روش ثابت. در ابتدا ، ما می توانیم نرخ یادگیری زیادی را تحمل کنیم. اما بعداً ، ما می خواهیم با نزدیک شدن به حداقل ، سرعت خود را کاهش دهیم. رویکردی که این استراتژی را پیاده سازی می کند ، بازپرداخت شبیه سازی شده یا نرخ یادگیری پوسیدگی نامیده می شود. در این مورد ، نرخ یادگیری هر تعداد ثابت تکرارها را پوسیده می شود.
چالش هایی با نزول شیب شماره 1: حداقل محلی
خوب ، تا کنون ، به نظر می رسد داستان نزول شیب واقعاً خوشحال است. خوب. بگذارید این را برای شما خراب کنم. به یاد داشته باشید وقتی گفتم عملکرد ضرر ما بسیار خوب است ، و چنین عملکردهای از دست دادن واقعاً وجود ندارد؟آنها این کار را نمی کنند.
اول ، شبکه های عصبی عملکردهای پیچیده ای هستند که بسیاری از تحولات غیرخطی در عملکرد فرضیه ما پرتاب می شوند. عملکرد از دست دادن نتیجه یک کاسه زیبا به نظر نمی رسد ، تنها با یک حداقل می توانیم به آن همگرا شویم. در حقیقت ، چنین توابع از دست دادن مانند سانتا مانند توابع محدب نامیده می شوند (کارکردهایی که همیشه به سمت بالا خمیده می شوند) ، و عملکردهای از دست دادن برای شبکه های عمیق به سختی محدب هستند. در واقع ، آنها ممکن است به این شکل باشند.
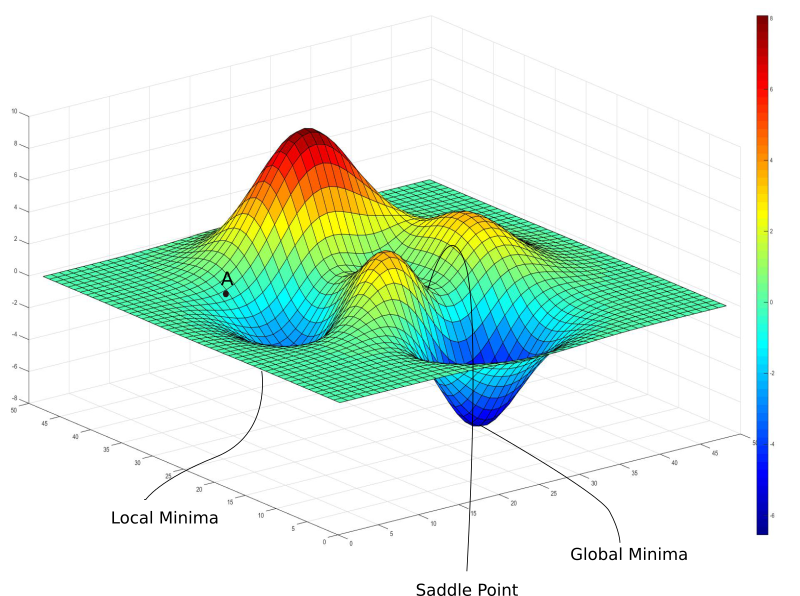
در تصویر فوق ، یک حداقل محلی وجود دارد که شیب صفر است. با این حال ، ما می دانیم که آنها کمترین ضرر و زیان ما می توانیم به دست بیاوریم ، این نقطه ای است که مربوط به حداقل جهانی است. حال اگر وزنهای خود را در نقطه A قرار دهید ، پس از آن به مینیما محلی همگرا می شوید ، و به هیچ وجه به هیچ وجه نزول شیب شما را از آنجا خارج نمی کند ، هنگامی که به مینیما محلی همگرا شوید.
نزول شیب توسط شیب هدایت می شود که در پایه هر حداقل صفر خواهد بود. حداقل محلی به این ترتیب خوانده می شود زیرا مقدار عملکرد ضرر در آن نقطه در یک منطقه محلی حداقل است. در حالی که ، یک مینیما جهانی به این ترتیب خوانده می شود زیرا مقدار عملکرد ضرر حداقل در آنجا است ، در سطح جهانی در کل دامنه عملکرد ضرر.
فقط برای بدتر شدن اوضاع ، کانتورهای ضرر حتی ممکن است پیچیده تر باشند ، با توجه به این واقعیت که کانتورهای 3 بعدی مانند نمونه ای که ما در نظر داریم هرگز در عمل اتفاق نمی افتد. در عمل ، شبکه عصبی ما ممکن است 1 میلیارد وزن داشته باشد ، با توجه به عملکرد تقریباً (1 میلیارد + 1) ما. من حتی تعداد صفرهای موجود در آن شکل را نمی دانم.
در واقع ، حتی تجسم چنین عملکردی ابعادی بالا حتی دشوار است. با این حال ، با توجه به استعدادی که این روزها در زمینه یادگیری عمیق است ، مردم راه هایی برای تجسم ارائه داده اند ، کانتورهای عملکرد از دست دادن در 3-D. مقاله اخیر پیشگامان تکنیکی به نام عادی سازی فیلتر است که توضیح می دهد که فراتر از محدوده این پست است. با این حال ، این دیدگاه از پیچیدگی های اساسی توابع ضرر که با آنها سر و کار داریم ، به ما می دهد. به عنوان مثال ، کانتور زیر یک نمایش 3 بعدی ساخته شده برای کانتور از دست دادن عملکرد از دست دادن شبکه Deep VGG-56 در مجموعه داده CIFAR-10 است.

اعتبار تصویر چشم انداز ضرر پیچیده: https://www. cs. umd. edu/~TOMG/پروژه ها/مناظر/
همانطور که مشاهده می کنید ، منظره ضرر با حداقل محلی سوار شده است.
چالش های مربوط به شیب نزول شماره 2: امتیاز زین
درس اساسی که در مورد محدودیت نزول شیب از آن استفاده کردیم این بود که پس از رسیدن به منطقه ای با شیب صفر ، فرار از آن تقریباً غیرممکن بود بدون توجه به کیفیت حداقل. نوع دیگری از مشکلی که ما با آن روبرو هستیم ، نقاط زین است که به نظر می رسد.
یک نقطه زین
همچنین می توانید یک نقطه زین را در عکس قبلی مشاهده کنید که در آن دو "کوه" ملاقات می کنند.
یک نقطه زین نام آن را از زین اسب که با آن شبیه است ، می گیرد. در حالی که این حداقل در یک جهت (x) است ، اما یک حداکثر محلی در جهت دیگری است ، و اگر کانتور به سمت جهت X مسطح تر باشد ، GD در جهت y نوسان و از آنجا می ماند و این توهم را به ما می دهد که مابه حداقل همگرا شده اند.
تصادفی در نجات!
بنابراین ، چگونه می توانیم در حال فرار از نقاط مینیما و زین محلی باشیم ، در حالی که سعی می کنیم به یک مینیما جهانی همگرایی کنیم. پاسخ تصادفی است.
تاکنون ما با عملکرد ضرر که با جمع بندی از دست دادن بیش از همه نمونه های ممکن از مجموعه آموزش ایجاد شده بود ، نزول شیب را انجام می دادیم. اگر وارد یک نقطه حداقل یا زین محلی شویم ، گیر کرده ایم. راهی برای کمک به GD از این موارد ، استفاده از آنچه به نام نزول شیب تصادفی گفته می شود.
در نزول شیب تصادفی ، به جای اینکه با محاسبه شیب عملکرد از دست دادن با جمع بندی تمام توابع ضرر ، قدم برداریم ، با محاسبه شیب از دست دادن تنها یک نمونه به طور تصادفی (بدون جایگزینی) یک قدم برداریم. برخلاف نزول شیب تصادفی ، جایی که هر مثال به صورت تصادفی انتخاب می شود ، رویکرد قبلی ما همه نمونه ها را در یک دسته واحد پردازش می کند ، و بنابراین ، به عنوان نزول شیب دسته ای شناخته می شود.
قانون به روزرسانی بر این اساس اصلاح شده است.
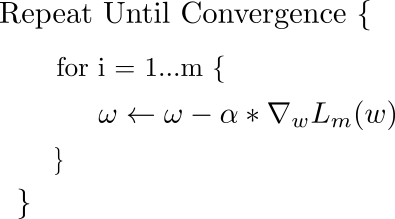
قانون را برای نزول شیب تصادفی به روز کنید
این بدان معناست که در هر مرحله ، ما شیب یک عملکرد ضرر را می گیریم ، که با عملکرد از دست دادن واقعی ما متفاوت است (که جمع بندی از دست دادن هر نمونه است). گرادیان این "یک نمونه از دست دادن" در یک خاص ممکن است در واقع در جهت متفاوتی با شیب "All-Exply-So-Loss" قرار بگیرد.
این همچنین بدان معنی است که در حالی که شیب "همه از دست دادن" ممکن است ما را به حداقل برساند ، یا ما را در یک نقطه زین گیر کند ، شیب "یک نمونه-از دست دادن" ممکن است در جهت دیگری قرار بگیرد، و ممکن است به ما کمک کند تا از این موارد دور شویم.
همچنین می توان نکته ای را در نظر گرفت که حداقل محلی برای "همه-از دست دادن" است. اگر ما در حال نزول شیب دسته ای هستیم ، از آنجا که شیب همیشه به حداقل محلی اشاره خواهد کرد ، در اینجا گیر خواهیم کرد. با این حال ، اگر ما از نزول شیب تصادفی استفاده می کنیم ، ممکن است این نقطه در یک حداقل محلی در کانتور ضرر "یک نمونه از دست دادن" قرار نگیرد و به ما امکان می دهد تا از آن دور شویم.
حتی اگر برای "یک نمونه از دست دادن" در حداقل گیر شویم ، منظره ضرر برای "یک نمونه از دست دادن" برای نقطه داده نمونه بعدی به طور تصادفی ممکن است متفاوت باشد و به ما امکان ادامه حرکت می دهد.
هنگامی که همگرایی می کند ، به جایی می رسد که تقریباً برای همه "ضایعات یک نمونه" حداقل است. همچنین از نظر امپراطوری نشان داده شده است که نقاط زین بسیار ناپایدار هستند و ممکن است یک گنگ جزئی برای فرار از یک مورد کافی باشد.
بنابراین ، آیا این در عمل به معنای آن است ، باید همیشه این نزول شیب تصادفی یک نمونه را انجام دهد؟
اندازه دسته
جواب نه. اگرچه از دیدگاه نظری ، نزول شیب تصادفی ممکن است بهترین نتیجه را به ما بدهد ، اما از یک نقطه محاسباتی گزینه ای بسیار مناسب نیست. هنگامی که ما نزول شیب را با یک عملکرد ضرر انجام می دهیم که با جمع بندی تمام تلفات فردی ایجاد می شود ، شیب تلفات فردی را می توان به صورت موازی محاسبه کرد ، در حالی که در صورت نزول شیب تصادفی باید به صورت متوالی محاسبه شود.
بنابراین ، کاری که ما انجام می دهیم یک عمل متعادل است. به جای استفاده از کل مجموعه داده ها ، یا فقط یک مثال واحد برای ساخت عملکرد از دست دادن خود ، ما از تعداد مشخصی از مثالها می گویند ، 16 ، 32 یا 128 برای شکل دادن به آنچه که مینی دسته نامیده می شود ، استفاده می کنیم. این کلمه در تقابل با پردازش تمام نمونه ها به طور هم زمان استفاده می شود ، که به طور کلی نزول شیب دسته ای نامیده می شود. اندازه Mini Batch انتخاب شده است تا اطمینان حاصل شود که ما به اندازه کافی تصادفی برای جلوگیری از حداقل محلی دریافت می کنیم ، در حالی که قدرت محاسبات کافی را از پردازش موازی استفاده می کنیم.
مینیما محلی تجدید نظر شده: آنها به همان اندازه که فکر می کنید بد نیستند
قبل از اینکه ماین مینیما محلی را تضعیف کنید ، تحقیقات اخیر نشان داده است که حداقل محلی به طور ضروری بد نیست. در چشم انداز ضرر یک شبکه عصبی ، حداقل بیش از حد بسیار زیاد است ، و یک مینیمای محلی "خوب" ممکن است به همان اندازه عملکرد جهانی داشته باشد.
چرا می گویم "خوب"؟از آنجا که شما هنوز هم می توانید در مینیما محلی "بد" گیر کنید که در نتیجه نمونه های آموزش نامنظم ایجاد می شود."خوب" حداقل محلی ، یا اغلب در ادبیات به عنوان حداقل محلی بهینه گفته می شود ، با توجه به عملکرد از دست دادن ابعادی بالای شبکه عصبی می تواند در تعداد قابل توجهی وجود داشته باشد.
همچنین ممکن است خاطرنشان شود که بسیاری از شبکه های عصبی طبقه بندی را انجام می دهند. اگر حداقل محلی با آن مطابقت داشته باشد و نمرات بین 0. 7-0. 8 را برای برچسب های صحیح تولید کند ، در حالی که مینیما جهانی برای برچسب های صحیح برای نمونه های مشابه نمرات بین 0. 95-0. 98 تولید می کند ، پیش بینی کلاس خروجی برای هر دو یکسان است.
یک خاصیت مطلوب از حداقل باید باشد که باید در سمت مسطح باشد. چرا؟از آنجا که حداقل مسطح به راحتی همگرایی می شود ، با توجه به اینکه شانس کمتری برای بیش از حد بیش از حد وجود دارد و بین پشته های مینیما تندرست می شود.
مهمتر از همه ، ما انتظار داریم که سطح از دست دادن تست تنظیم شده کمی متفاوت از مجموعه آموزش باشد ، که در آن آموزش خود را انجام می دهیم. برای حداقل مسطح و گسترده ، ضرر به دلیل این تغییر تغییر زیادی نخواهد کرد ، اما این مورد برای حداقل باریک نیست. نکته ای که ما در حال تلاش برای بیان آن هستیم ، مینیما مینیما تعمیم یافته است و از این رو مطلوب است.
نرخ یادگیری مجدداً مورد بررسی قرار گرفت
به تازگی ، تحقیقات در مورد برنامه ریزی نرخ یادگیری افزایش یافته است تا حداقل به حد مطلوب در چشم انداز ضرر را به خود اختصاص دهد. حتی با وجود نرخ یادگیری پوسیدگی ، می توان در یک حداقل محلی گیر کرد. به طور سنتی ، یا آموزش برای تعداد مشخصی از تکرارها انجام می شود ، یا می توان آن را متوقف کرد ، مثلاً 10 تکرار پس از بهبود ضرر. این امر به عنوان توقف زود هنگام ادبیات خوانده می شود.
داشتن نرخ یادگیری سریع همچنین به ما کمک می کند تا در اوایل آموزش حداقل محلی را به دست بیاوریم.
مردم همچنین توقف زود هنگام با پوسیدگی نرخ یادگیری را ترکیب کرده اند ، جایی که نرخ یادگیری پس از هر زمان که ضرر پس از 10 تکرار بهبود نمی یابد ، پوسیده می شود ، در نهایت متوقف می شود پس از آنکه نرخ زیر آستانه تصمیم گیری است.
در سالهای اخیر ، میزان یادگیری چرخه ای محبوب شده است که در آن میزان یادگیری به آرامی افزایش می یابد و سپس کاهش می یابد و این به صورت چرخه ای ادامه می یابد.
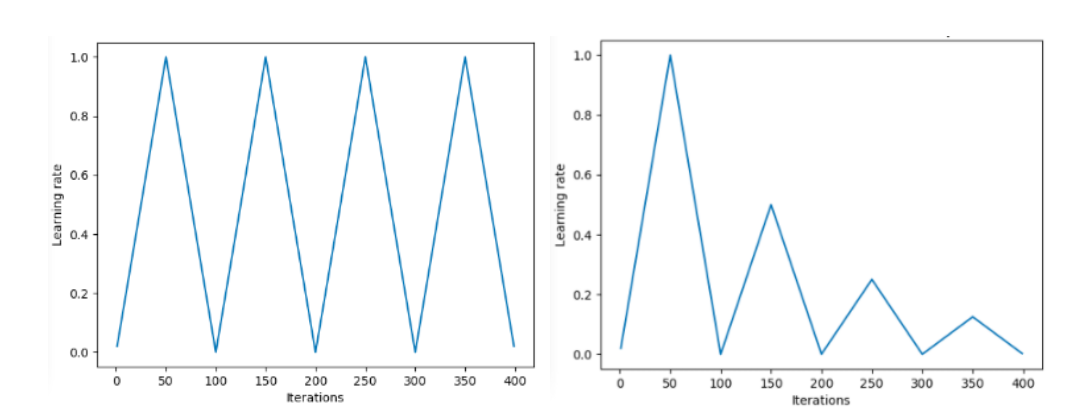
روشهای "مثلثی" و "مثلثی 2" برای میزان یادگیری دوچرخه سواری که توسط لسلی N. اسمیت پیشنهاد شده است. در نقشه سمت چپ MIN و MAX LR یکسان نگه داشته می شوند. در سمت راست ، اختلاف بعد از هر چرخه به نصف کاهش می یابد. اعتبار تصویر: Hafidz Zulkifli
چیزی به نام نزول شیب تصادفی با شروع مجدد گرم اساساً میزان یادگیری را به یک مرز پایین تر نشان می دهد و سپس نرخ یادگیری را به ارزش اصلی آن باز می گرداند.
ما همچنین برنامه های مختلفی در مورد چگونگی کاهش نرخ یادگیری ، از پوسیدگی نمایی گرفته تا پوسیدگی کوسین داریم.
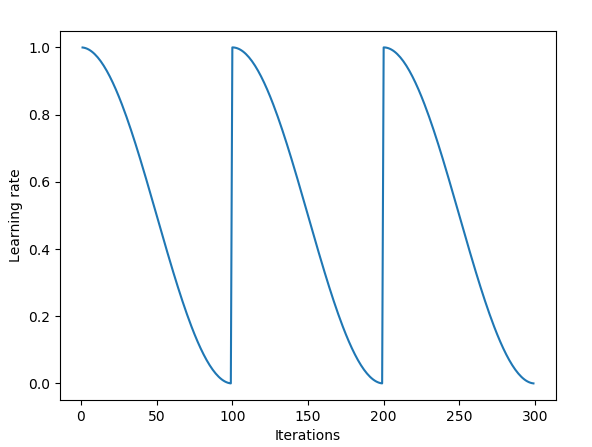
بازپرداخت كسین همراه با راه اندازی مجدد
مقاله بسیار اخیر تکنیکی به نام میانگین وزن تصادفی را معرفی می کند. نویسندگان رویکردی را ایجاد می کنند که ابتدا به حداقل می رسند ، وزنه ها را ذخیره می کنند و سپس نرخ یادگیری را به یک مقدار بالاتر باز می گردانند. این نرخ یادگیری عالی سپس الگوریتم را از حداقل به یک نقطه تصادفی در سطح از دست دادن سوق می دهد. سپس الگوریتم ساخته شده است تا دوباره به حداقل دیگر همگرا شود. این برای چند بار تکرار می شود. سرانجام ، آنها پیش بینی های انجام شده توسط تمام مجموعه وزن های ذخیره شده را برای تولید پیش بینی نهایی انجام می دهند.
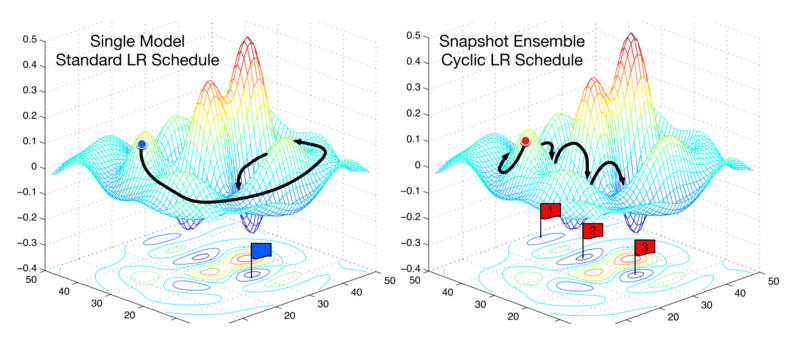
تکنیکی به نام میانگین وزن تصادفی
نتیجه
بنابراین ، این پست مقدماتی در مورد نزول شیب بود ، که اسب کار برای بهینه سازی یادگیری عمیق از زمان مقاله منی در زمینه بازگشت به عقب بود که نشان می داد شما می توانید شبکه های عصبی را با شیب های محاسباتی آموزش دهید. با این حال ، هنوز یک بلوک از دست رفته در مورد نزول شیب وجود دارد که در این پست درباره آن صحبت نکرده ایم ، و این مسئله مشکل انحنای پاتولوژیک است. از پسوندها به نزول شیب تصادفی وانیل ، مانند Momentum ، RMSProp و Adam برای غلبه بر این مشکل حیاتی استفاده می شود.
با این حال ، من فکر می کنم هر کاری که انجام داده ایم برای یک پست کافی است و بقیه آن در پست دیگری پوشانده می شود.
استراتژیهای اسکالپ...
ما را در سایت استراتژیهای اسکالپ دنبال می کنید
برچسب : نویسنده : ناصر تقوایی بازدید : 38
